데이터베이스백엔드
When developing services that handle large amounts of data, implementing pagination is an inevitable part of modern development. In this post, I’ll discuss examples ranging from basic pagination to more advanced pagination features worth exploring.
Generally, Pagination(페이지네이션) refers to sorting a large amount of data according to certain criteria and then displaying it in batches of a specific size. Since each group of data—divided into specific quantities—is called a “page,” this process is referred to as pagination. Common examples of pagination include bulletin board-style layouts and auto-scroll features.
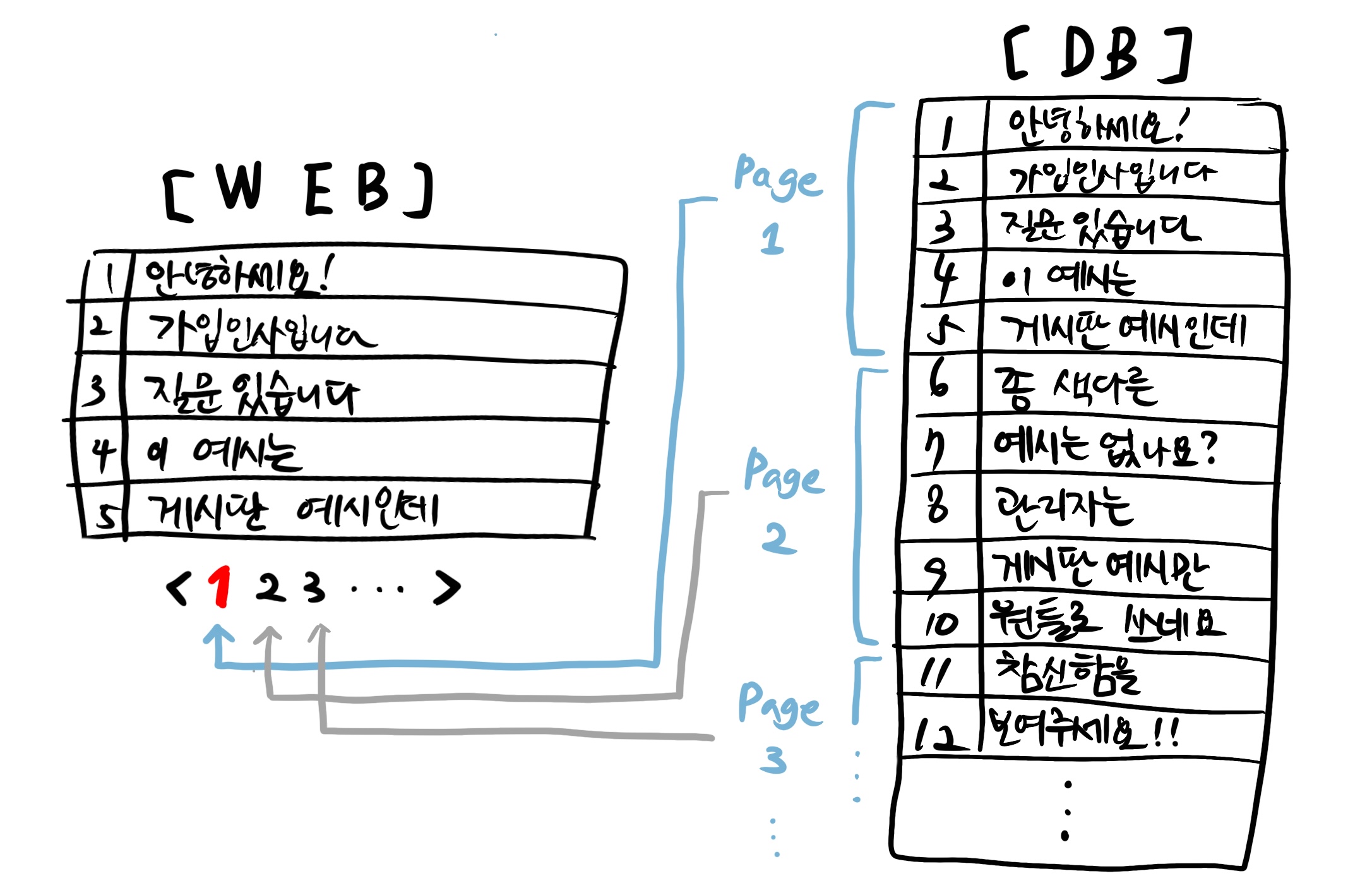
It is very common for a backend engineer to receive a request like, “Please create an API that retrieves a list of posts with pagination.” To solve this, it is standard practice to use a query via an ORM.
Until now, I have used the following queries to implement pagination.
sqlselect * from boards limit 5 -- page의 사이즈 offset 10 -- (page 번호 - 1) * page 사이즈
Traditionally, pagination can be achieved using limit and offset. If we implement this using Flask and the SQLAlchemy API, we can create an API with pagination functionality like the following.
python@app.route("/api/boards") def get_boards(page, page_size): offset_num = (page - 1) * page_size boards = ( Board.query .limit(page_size) .offset(offset_num) .all() ) return [ board._asdict() for board in boards ]
While researching for this blog post, I came across the opinion that “we shouldn’t use offset!”—which I found to be quite reasonable. However, since this is slightly off-topic for this post, I plan to study it further and summarize my findings later. Reference blog 👉 https://binux.tistory.com/148
If we add sorting and search functionality to the example above, we can implement a general API for retrieving lists of data.
Then one day, I received this request from a product manager:
Please add a feature that automatically finds the ‘page number’ for a given post!
From a developer’s perspective, this request could be rephrased as follows:
Please calculate the page number in reverse using the post’s ID.
When I first heard this, I thought, “Huh? That sounds like an unfamiliar and difficult feature. Is it even possible…?” However, since they said it was absolutely! necessary from a functional standpoint, I checked to see if I could solve it technically.
I started by writing a query in PostgreSQL. I wrote a query that could find the page for each ID.
sqlselect b.id, (row_number() over() - 1) / 10 + 1 as "page_num" -- 여기서 나눈 10이 page_size from board b order by b.id
The logic for calculating page_num can be broken down as follows:
ROW_NUMBER() OVER (): This is a function that assigns an order to the current row. Here, it’s used to number all rows.1: Subtract 1 to set the order of the first row to 0./ 10: Divides each row’s index by page_size (10 in this case) to find the quotient. This ensures that every 10 rows share the same value.Let’s verify the following results using a simple example.
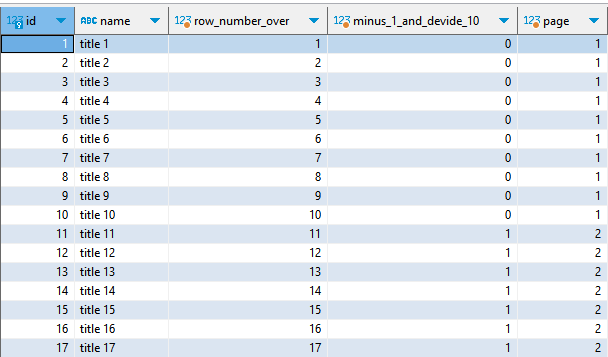
There are approximately 100 records in a table named
boards. Let’s create a query that returns the page number for each row—for pagination purposes only—when the table is sorted byid.
sqlselect b.id, b.name, row_number() over() as "row_number_over", (row_number() over() - 1) / 10 as "minus_1_and_devide_10", (row_number() over() - 1) / 10 + 1 as "page" from board b order by b.id
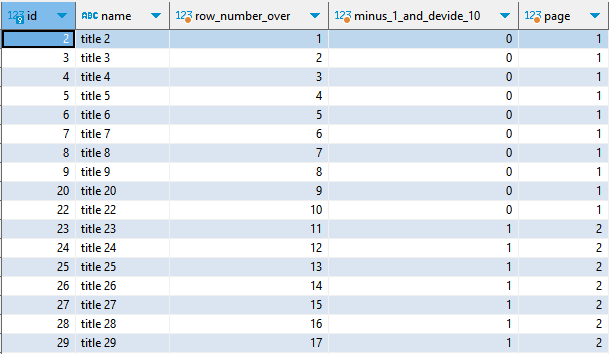
How should we handle cases where the
namein the table above does not contain '1'?
sqlselect b.id, b.name, row_number() over() as "row_number_over", (row_number() over() - 1) / 10 as "minus_1_and_devide_10", (row_number() over() - 1) / 10 + 1 as "page" from board b where b.name not like '%1%' order by b.id
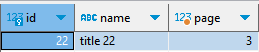
Now, if we retrieve the content ID from here and apply a WHERE clause, we can obtain the page number for that specific content.
💡 Important Note
At this point, you must use the query above as a subquery and apply aWHERE id = {id}condition. If you include it directly in theWHEREclause of the example above, it will be used in the page calculation, so you won’t get the desired page number.
sqlselect * from ( select b.id, b.name, (row_number() over() - 1) / 10 + 1 as "page" from board b order by b.id ) A -- subquery를 이용해야 한다 where A.id = 22
My biggest concern when developing this feature was 속도. The reason was that I wondered, “If the number of data records increases due to the row_number() over() syntax, won’t the calculation speed naturally slow down?” I reasoned that with 1 million data points, the time required to calculate the row order for each data point would increase to at least O(n), even under the most optimistic estimate. So, I tested it by gradually adding data.
Using the EXPLATIN ANALYZE syntax, you can check the query execution plan and how much time each phase takes.
I’ve reused the query from above, but this time I’ve included the EXPLATIN ANALYZE syntax as well.
sqlEXPLAIN ANALYZE select * from ( select B.id, B.name, (row_number() over() - 1) / 10 + 1 as "page" from board B order by B.id ) A where A.id = 100
The query execution plans and execution times for cases with only the data in 100개 and cases with the data in 100만개 are as follows.
When the board table contains 100 records

When the board table contains 1 million rows

We observed that when the data increased by a factor of 10,000, the execution time increased by approximately 5,560 times. In fact, with 1 million rows, the query alone took 0.5 seconds, resulting in a noticeable delay. We confirmed that if additional logic were added at the server API handler level, the API call itself could become quite slow.
LIMIT clause to the subquery.In this case, the LIMIT clause is used to reduce the time spent sorting rows in the subquery before calculating the page.
sqlEXPLAIN ANALYZE select * from ( select B.id, B.name, (row_number() over() - 1) / 10 + 1 as "page" from board B order by B.id limit :target_id -- 이곳이 추가가 된다. 여기서 target_id는 변수로 사용 ) A where A.id = :target_id -- target_id를 변수로
Doing this reduces the time to retrieve a page of 100 records back down to around 0.002 seconds. However, this is not a fundamental solution. Retrieving a page of 1 million records still takes around 0.4 seconds.
The reasoning behind this approach is that retrieving all the data would be faster than row_number() over(), and by using binary search, the time complexity could be reduced to O(log n).
sqlEXPLAIN ANALYZE select * from board

row_number() over().pythondef binary_search_row_number(target_id, boards): # 해당 id가 전체 데이터에서 몇 번째에 있는지 계산하기 위해 binary search로 찾는다. board_idx_dict = { board.id: row_number for row_number, board in enumerate(boards) } low = 0 high = TOTAL_NUMBER target_index = high // 2 while low < high: target_index = board_idx_dict.get(target_id) if target_index is None: break if target_index > now_index: low = now_index elif target_index < now_index: high = now_index else: # target_index == now_index break now_index = (high + low) // 2 return target_index @app.route("/api/boards") def get_boards(page, page_size, target_id=None): # 자동으로 페이지를 계산하기 위해 여기를 추가 =========== if target_id is not None: # 예제는 전체 데이터를 가져왔지만, 정렬 / 필터 등이 들어가면 id가 곧 행 순서 번호가 되지 않을 수 있다. total_boards = Board.query.all() auto_page = (binary_search_row_number(target_id) - 1) / page_size + 1 if auto_page: page = auto_page # ================================================ offset_num = (page - 1) * page_size boards = ( Board.query .limit(page_size) .offset(offset_num) .all() ) return [ board._asdict() for board in boards ]
In real-world work, situations often arise where you need to apply additional functionality to basic features. In such cases, while you can solve the problem with a query, it’s also worth assessing whether a solution can be implemented at the query or backend code level to an appropriate extent. Of course, there’s no single “absolutely correct” method, but there are certainly “better” approaches.
This topic was something I hadn’t fully resolved yet (though it hasn’t been a major issue since the data volume is still small), but I’m glad it gave me the opportunity to reflect on it and study ways to improve—it was a valuable learning experience. I’ll make sure to implement these improvements properly in the future.